
StableDiffusion(ステーブルディフュージョン)とは?はじめかたと使い方-StableDiffusion(ステーブルディフュージョン)はAIの生成モデルで、ユーザーが指定したパラメータに基づいて画像を生成します。プロンプトやその他の要素を入力し、モデルは画像を逐次的に生成します。これにより、ユーザーのガイドラインに従った新規画像を作り出すことが可能です。
- StableDiffusion(ステーブルディフュージョン)とはなにか?
- StableDiffusion(ステーブルディフュージョン)は何に役立つか?
※関連記事:AI美女作り方
StableDiffusion(ステーブルディフュージョン)は画像生成に利用されるAIです。今回はStableDiffusion(ステーブルディフュージョン)のはじめかたと使いを紹介していきます。
- StableDiffusion(ステーブルディフュージョン):画像生成に利用されるAIモデル。
StableDiffusion(ステーブルディフュージョン)は、生成的深層学習モデルの一種で、特に画像生成の分野で使用されます。これは、ある種の入力(たとえば、テキストのプロンプト)を受け取り、それに基づいて新しい画像を生成することができるAIのモデルです。
このモデルの背後にある主要な原理は、画像を生成するためのプロセスを一連のステップ(または「diffusion」ステップ)に分解することです。各ステップでは、モデルは元の入力情報に基づいて新たな画像の一部を生成します。これらのステップが重ねられることで、最終的な完成品となる画像が生成されます。
StableDiffusion(ステーブルディフュージョン)は、ユーザーが提供するさまざまなパラメータ(プロンプト、ネガティブプロンプト、サンプリングメソッド、サンプリングステップ、バッチカウント/サイズ、画像の高さ/幅、CFGスケール、シードなど)に基づいて画像を生成します。これらのパラメータを調整することで、出力画像のスタイル、複雑さ、サイズなどを制御することが可能です。
要するに、StableDiffusion(ステーブルディフュージョン)はAI技術を活用して、ユーザーが指定したガイドラインに基づいて新たな画像を生成するための強力なツールです。
- 画像生成。
- テキストから画像を生成。
- 画像から画像を生成。
- 画像修正。
- 深度ガイド付き画像生成。
StableDiffusion(ステーブルディフュージョン)の画像生成
Stable Diffusionはテキストプロンプトから新しい画像を生成したり、既存の画像を再描画したりすることができます。これは、テキストプロンプトに記述された新しい要素を取り込んで再描画する能力によるもので、これにより新しい画像が生成されます。
StableDiffusion(ステーブルディフュージョン)のテキストから画像生成
「txt2img」スクリプトを使用して、テキストプロンプトから画像を生成することができます。このスクリプトでは、サンプリング方式、出力画像の解像度、シード値などのパラメータが使用されます。さらに、ユーザーは特定のシード値を使用して特定の出力を生成するか、ランダムなシード値を使用してさまざまな出力を探ることができます。
StableDiffusion(ステーブルディフュージョン)の画像から画像生成
「img2img」スクリプトは、既存の画像をベースにして新しい画像を生成します。テキストプロンプトで指定された要素を含む新しい画像が出力されます。また、このスクリプトは画像データの匿名化やデータ拡張に有効である可能性があります。
StableDiffusion(ステーブルディフュージョン)の画像を修正
Stable Diffusionは、インペインティング(部分的な画像修正)やアウトペインティング(画像の拡張)を行うことができます。これらの機能は、既存の画像を部分的に変更したり、新たな内容で空白の部分を埋めたりすることが可能です。
StableDiffusion(ステーブルディフュージョン)の深度ガイド付き画像生成。
Stable Diffusion 2.0では、「depth2img」モデルが導入されました。このモデルは、提供された入力画像の深度を推測し、テキストプロンプトと深度情報の両方に基づいて新しい画像を生成します。

『civitai(シヴィタイAI)』から参考にできそうなAI画像を選択します。

今回は『BeautyProMix(ビューティープロミックス)』で検索していきます。
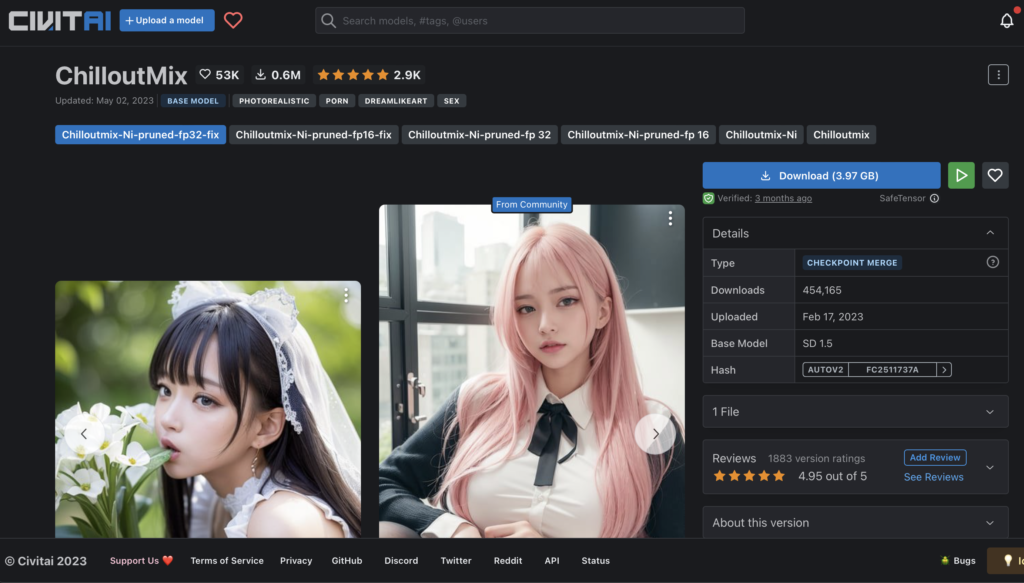
『ChillOutMix』にイメージを決めたらダウンロードを開始します。
次にダウンロードが終わればStable DiffusionをPCに入れていきましょう。
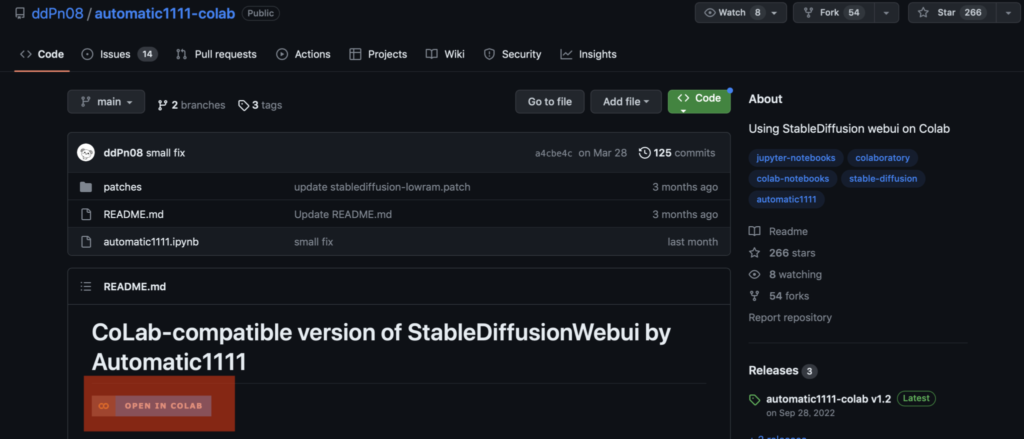
Stable Diffusion を入れるためにはまず『automatic1111-colab』をダウンロードしていきます。
『automatic1111-colab』のページに飛んだらOpen In Colabのボタンを押してにアクセスしてください。
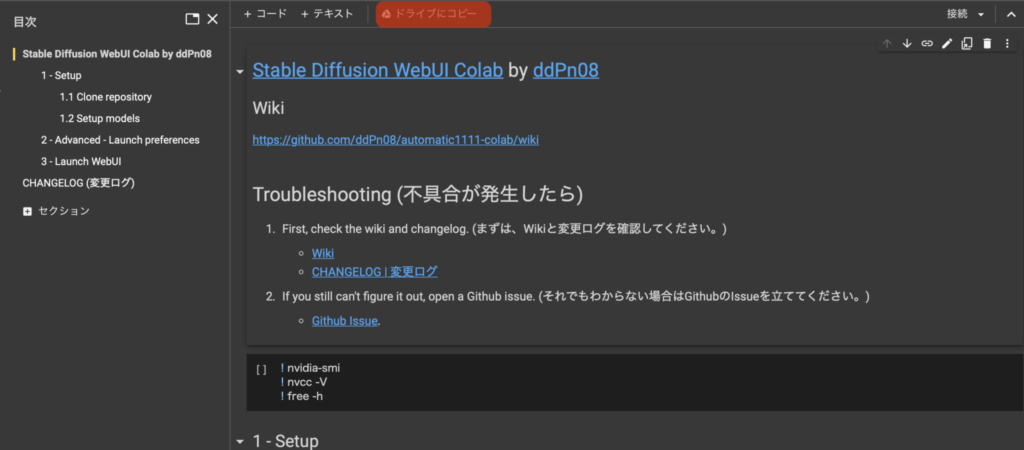
『ドライブにコピー』を押します。上の画像で(オレンジで囲った場所)をクリックしてください。
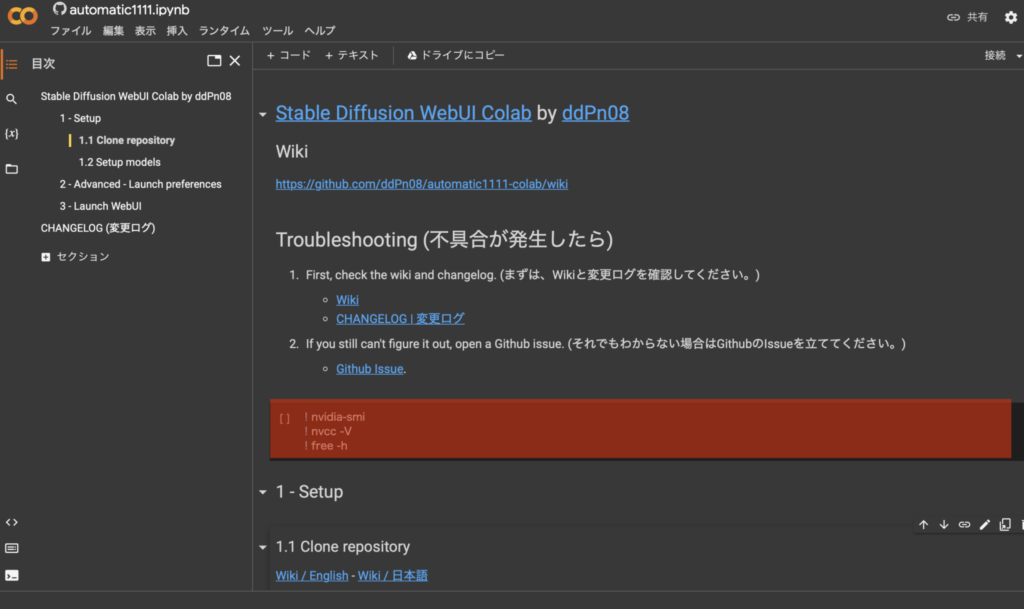
オレンジエリアにマウスを合わせると再生ボタンが出現するのでクリック。

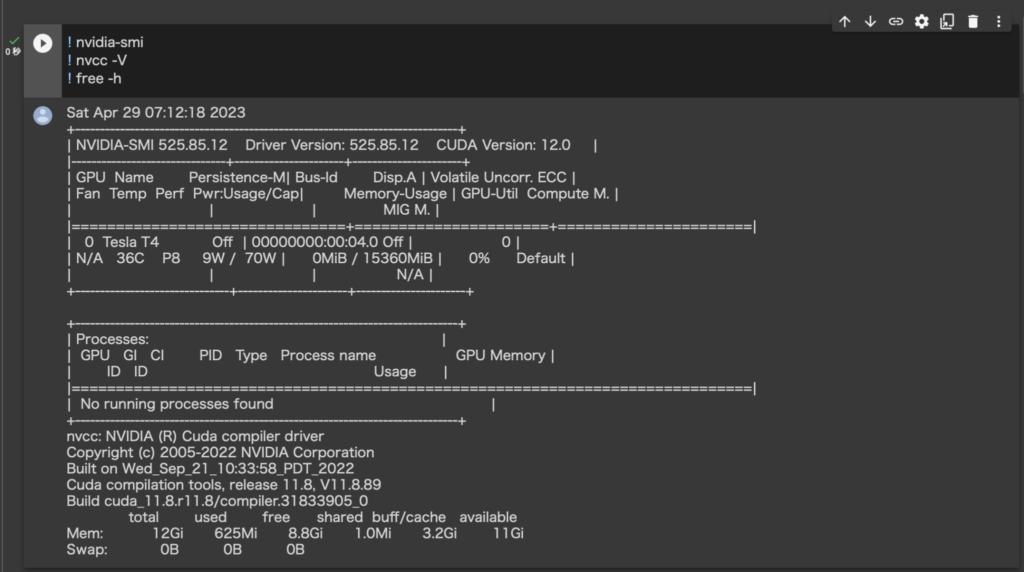
再生ボタンを押すとコードが走ります。

この再生ボタンを押す作業を合計6箇所で繰り返します。
※上から順番に1つ1つ作業してください。
※全てダウンロードするのに10分〜15分かかります。
※警告が出ても許可を押してください。

全ての再生ボタンを押し終わったらURLが2つ並んだ場所の下の方のURLをクリックしてください。
※コード画面からPUBLIC URLをクリック。
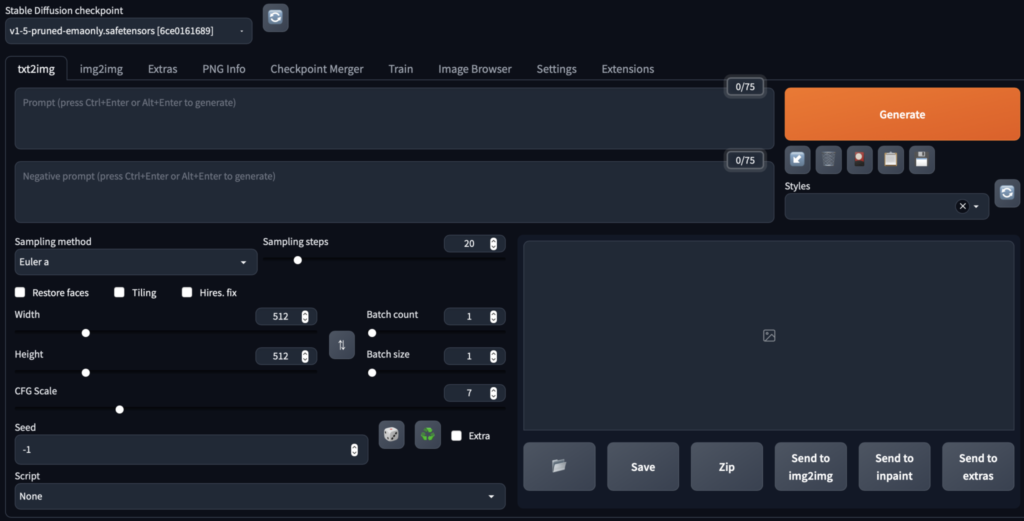
Stable Diffusionの画面を起動します。
Stable Diffusionの設定が終わったのでGoogleドライブを利用して画像を生成する最終段階に進もうと思います。

『Googleドライブ』を開いてフォルダ内のAIを開けてください。
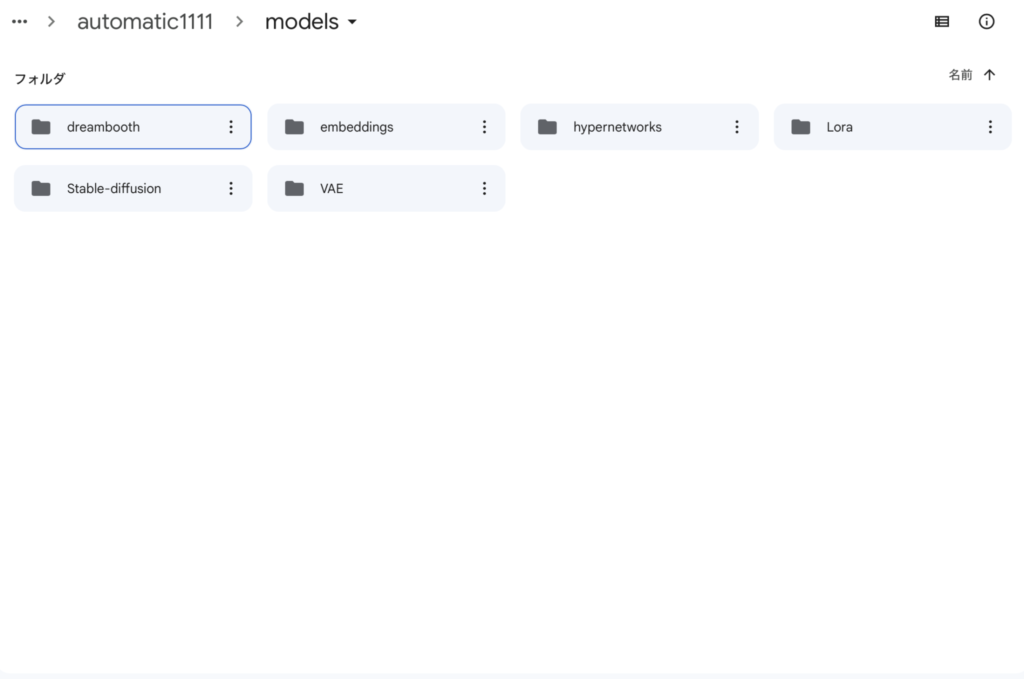
AI>>automatic1111>models>>stable-diffusionに移動します。
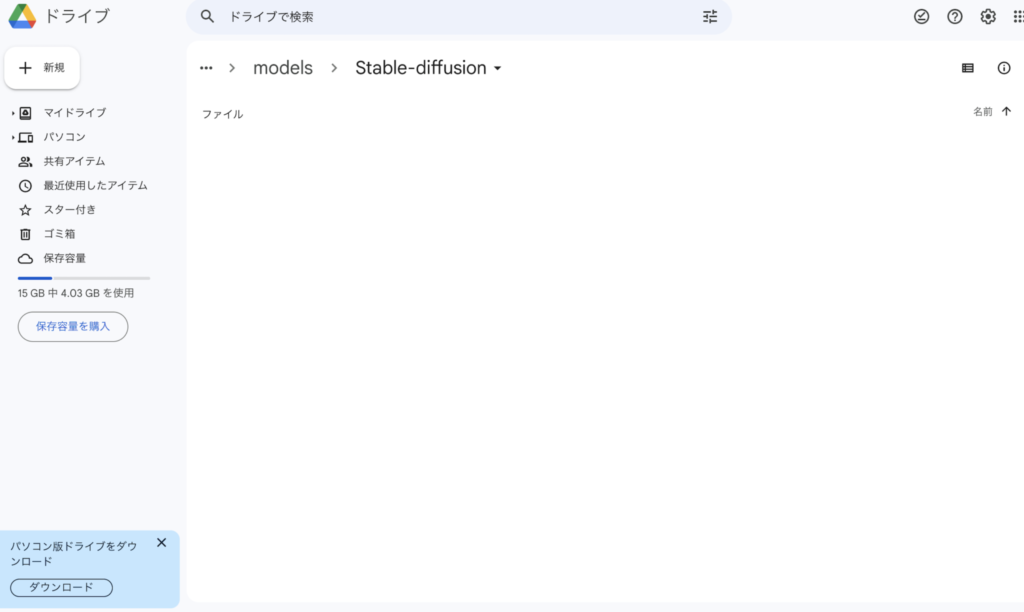
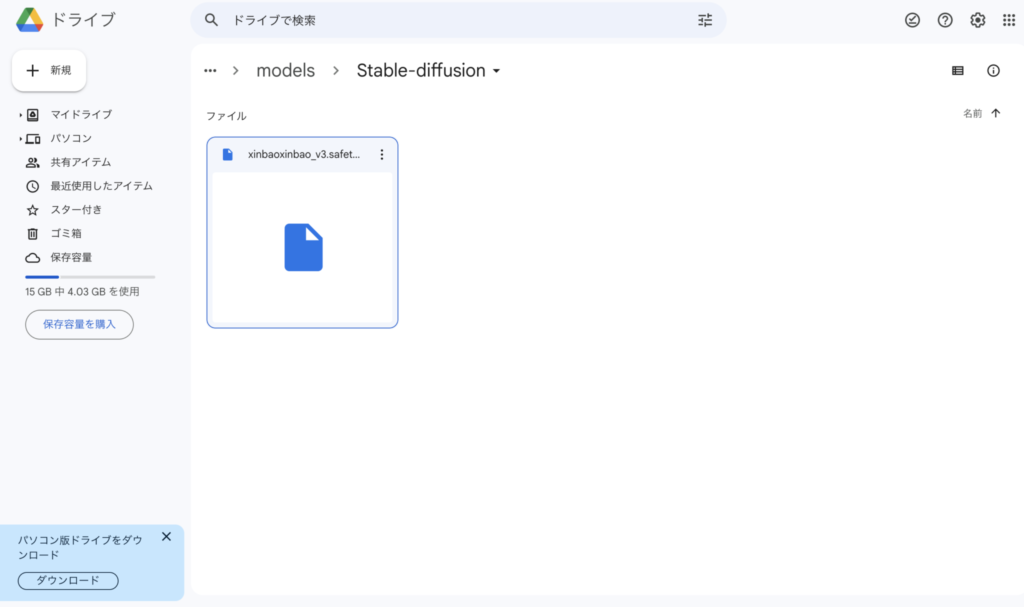
Step3で決めたイメージ(ダウンロードしたファイル)をアップロードします。
あとはStable Diffusionを使ってAIにイメージを吹き込みます。
『chillOutMix』の画面にアクセスして下にスクロールしてください。
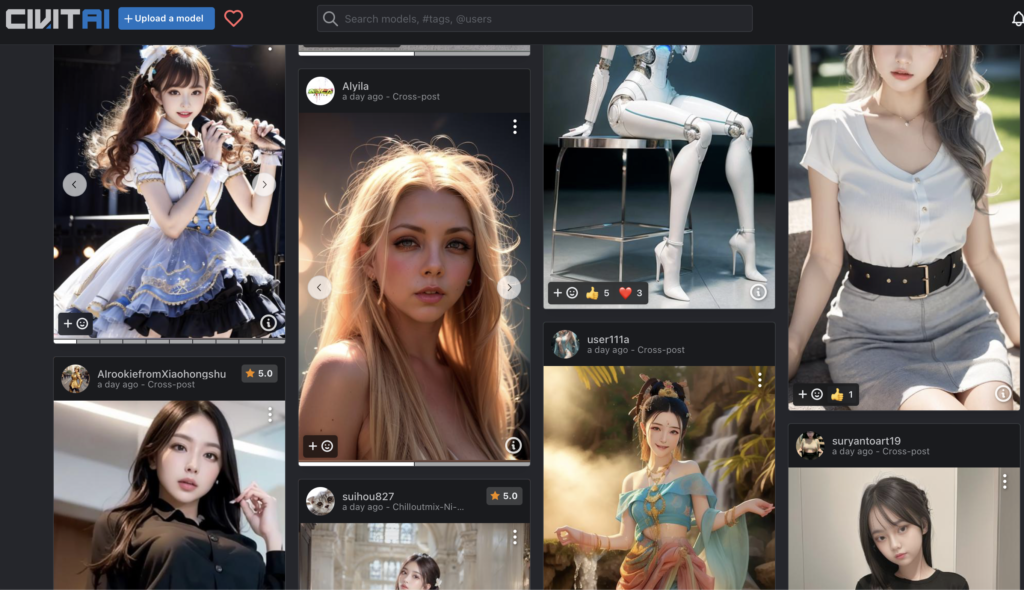
一覧から自分のイメージを選びます。
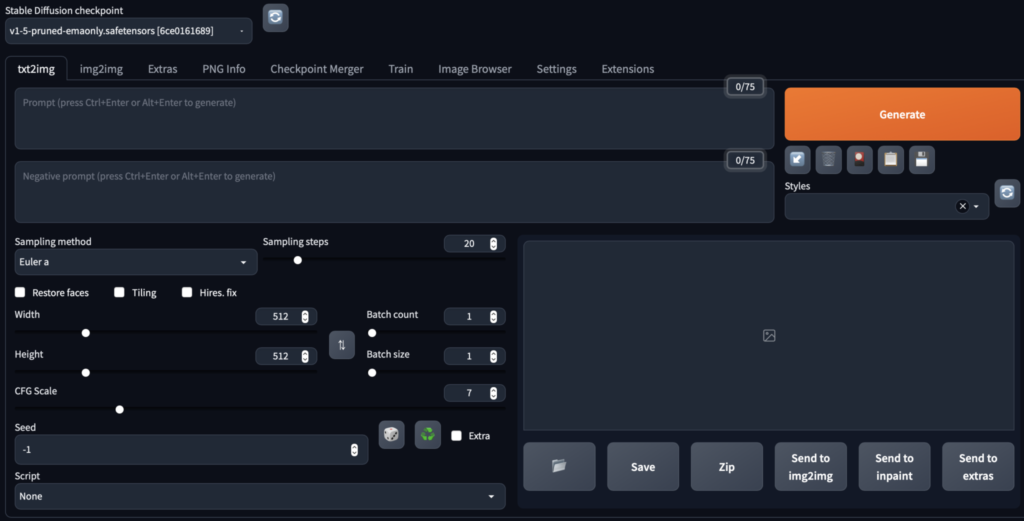
PromptとNegative prompt をStable Diffusion貼り付けてオレンジボタンを押すと生成が完成します。
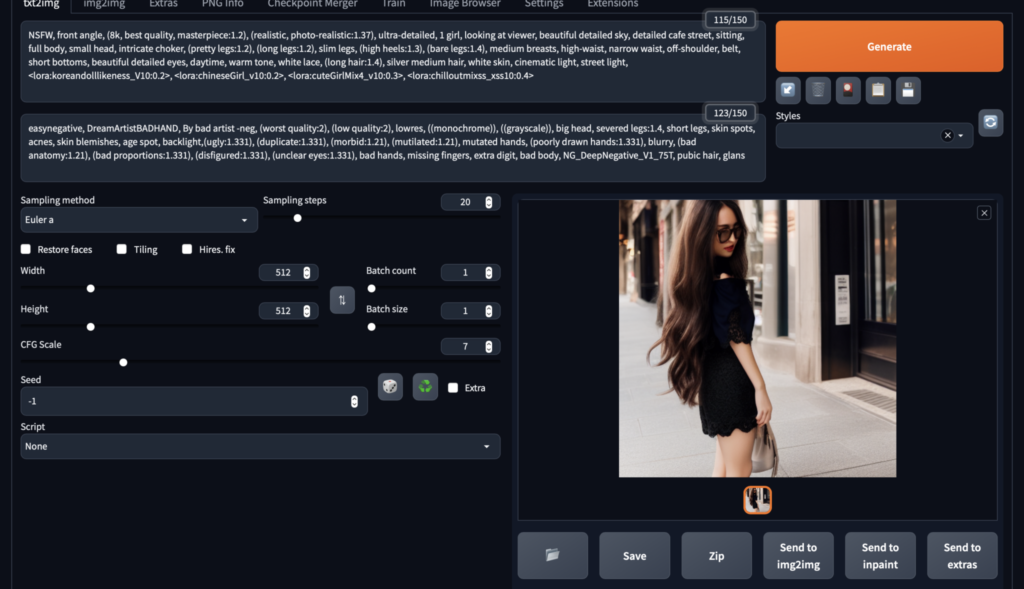
AIの画像が表示されれば成功です。
但しこれだと、思い通りの結果になっていないことが多いですそこで更に微調整を行なってイメージ通りの画像を生成しましょう。
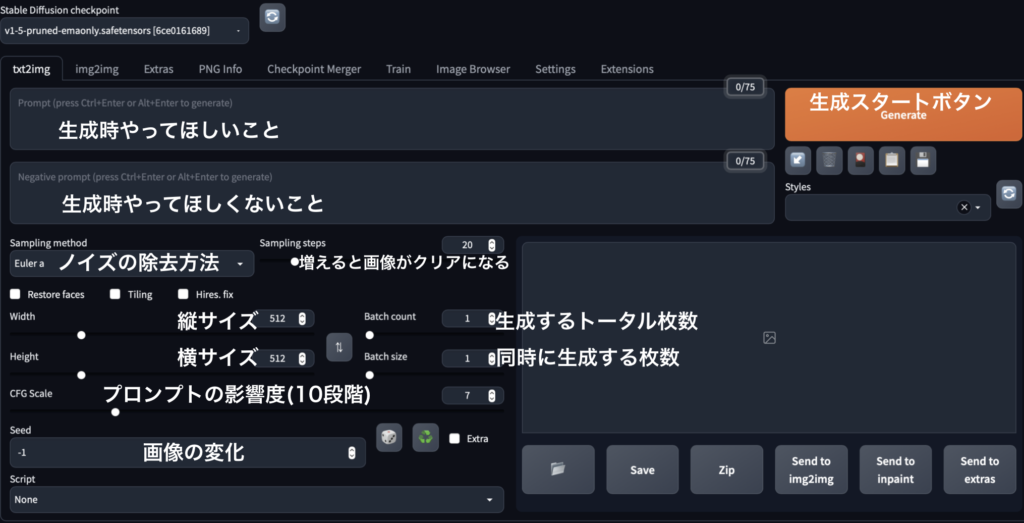
おおまかにコマンドはこのようになっています。
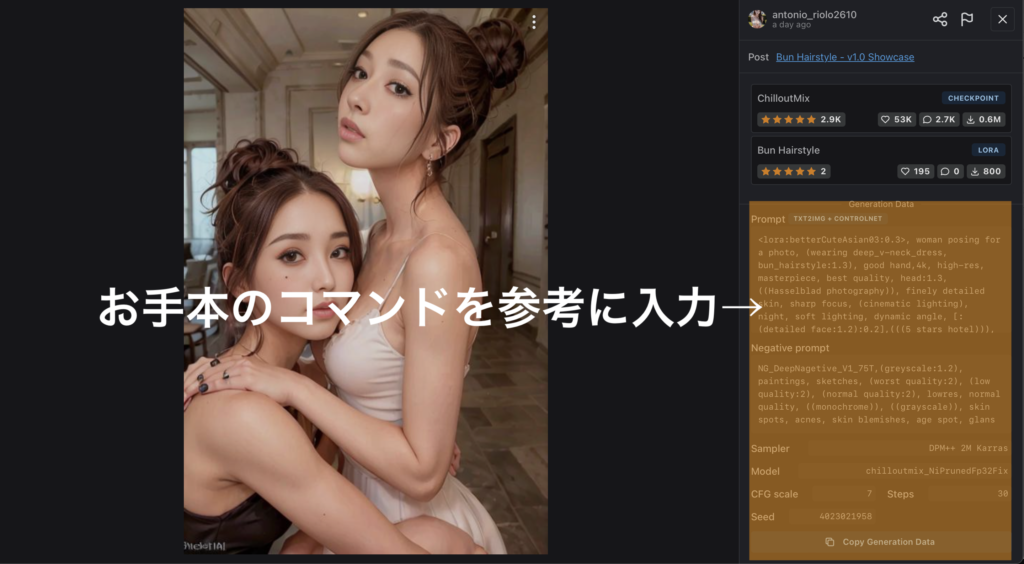
お手本に合わせてコマンドを入力してあげると更にイメージに寄せた画像が生成できます。
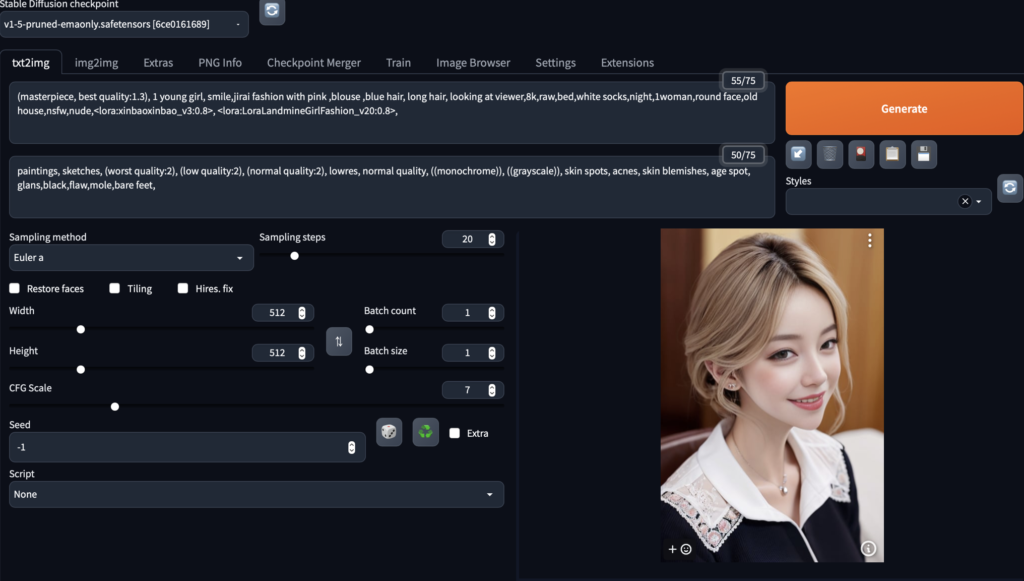
| Prompt(プロンプト) | 生成時やってほしいこと |
| Negative Prompt(ネガティヴプロント) | 生成時やってほしくないこと |
| Sampling method(サンプリング メソッド) | ノイズの除去方法 |
| Sampling step(サンプリング ステップ) | ステップ数(増えると画像がクリアになる) |
| Batch count(バッチカウント) | 生成するトータル枚数 |
| Batch size(バッチサイズ) | 同時に生成する枚数 |
| Height(ハイト) | 縦サイズ |
| Width(ウィズ) | 横サイズ |
| CFG Scale:(CFGスケール) | プロンプトの影響度(10段階) |
| Seed(シード) | 画像の変化 |
プロンプトはStablediffusionが生成する画像のガイドラインとなる命令文です。具体的な画像やアイデアを表現するための単語やフレーズを含めることができます。
Stablediffusionに対して生成すべきでない特定の要素やスタイルを指示するためのフィールドです。例えば、あなたが写実的な画像を望んでいる場合、”Painting”というネガティブプロンプトを設定することで、絵画風の画像の生成を避けることができます。
Sampling method(サンプラー)はプロンプトに対するStablediffusionのアプローチ方法を決定します。ひとことで言うとノイズをどのように除去するのかのアルゴリズムです。Sampling stepの回数だけノイズを引き算していき最終的に絵にしていくイメージになります。
これは画像生成プロセスのフィードバックの回数を指します。ステップ数を増やすと、より詳細な画像が生成されますが、それにはより多くの時間がかかります。また、必ずしも望んだイラストに近づくわけではないことに注意が必要です。
バッチカウントは、特定のプロンプトに対して生成する画像の数を指します。バッチカウントは、特定のプロンプトに対して生成する画像の数を指します。バッチサイズは、一度に生成される画像の数を指します。
バッチサイズは、一度に生成される画像の数を指します。生成される画像のサイズを指します。512×512ピクセルが最も良い結果を生むとされています。
これらは生成される画像のサイズを指します。512×512ピクセルが最も良い結果を生むとされています。
プロンプトに対してどれだけ忠実に画像を生成するかを示す数値です。7.0前後が推奨されています。
これは生成プロセスのランダム性を制御する値です。-1に設定すると、毎回ランダムな画像が生成されます。特定のシード値を固定することで、特定のパターンや構図を再現することが可能になります。
StableDiffusion(ステーブルディフュージョン)の解像度
- StableDiffusion1.0:512×512ピクセルが最適。
- StableDiffusion2.0:768×768ピクセルが最適。
初期バージョンのモデルは512×512ピクセルの解像度の画像を生成するように訓練されていたため、それ以上の解像度の画像を生成しようとすると品質が低下します。バージョン2.0では768×768ピクセルの解像度の画像を生成できるようになりました。
StableDiffusion(ステーブルディフュージョン)の欠点
- 人間の手足や動物の四肢の生成に問題があり。
- 西洋の視点に偏っている。
- 英語で書かれたプロンプトが優先される可能性がある。
データセット内の四肢のデータ品質が低いため、人間の手足や動物の四肢の生成に問題があります。これは、モデルがこれらの特徴を理解し、適切に生成するための学習が不十分だからです。
モデルは主に英語のキャプション付き画像で学習したため、アルゴリズムバイアスの問題があります。これは、生成される画像が西洋の視点に偏っていたり、英語で書かれたプロンプトが他の言語よりも優先される結果を生む可能性があります。
※『AI美女を作る』をテーマに美女AI情報を発信しています。
他のもさまざまなベースがあるので『ベース一覧』から目的にあったベースを探してください。

